ソフトウェアの品質評価モデル
| ソフトウェアの品質評価を行う際に使用するモデルについて、主なものをまとめる。 ここで取り上げるモデルは、 ・信頼度成長曲線 ・ゾーン分析 ・パレート図 ・管理図分析 と呼ばれるものである。 各モデルの説明は以下の図書を参考にした。 「定量的品質予測のススメ」(IPA オーム社) 「続 定量的品質予測のススメ」(IPA オーム社) 「ソフトウェアメトリクス統計分析入門」(小池利和:著 日科技連) |
||||||||||||||||||||
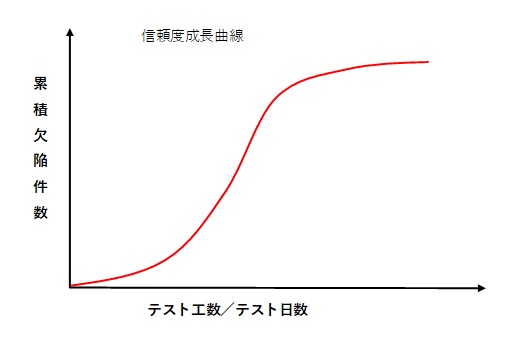
(1)信頼度成長曲線テスト工程で発生した障害(不具合、欠陥)の収束状況を評価するために使用するケースが多い。
教科書的には、設計工程における使用例(設計ドキュメントのレビューで検出した欠陥数を評価する)も見られるが、(私の経験では)テスト工程で使われるケースがほとんどである。
テスト工程で信頼度成長曲線を使う場合は、縦軸に障害数(欠陥数)を、横軸には日付やテスト日数を置く場合が多い。(横軸はテスト密度が出来るだけ均等になるように配置するのが望ましい)
代表的な信頼度成長モデル(SRGMモデル)には、
ゴンペルツ曲線、ロジスティック曲線、指数形モデル、遅延S字形モデル
がある。
テスト工程で信頼度成長曲線を使う場合、以下2つの局面がある。
①テストを実施している途中段階で、障害検出数が目標値を達成しそうか否か、を予測する。
②テストが完了した段階で、障害の収束状況を評価する。
①で障害検出数を予測する場合、一般的にはテスト消化率が60%以上でないと予測は難しい。
|
||||||||||||||||||||
 |
||||||||||||||||||||
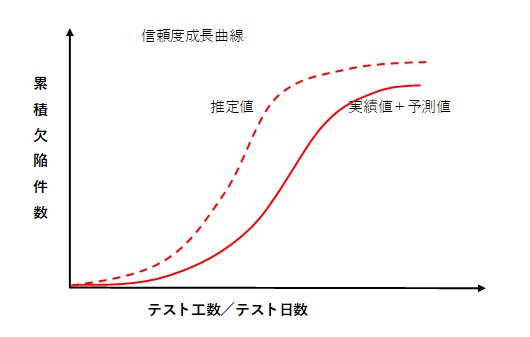 完了時点の予測値が目標値を下回る場合、 完了時点の予測値が目標値を下回る場合、テストの網羅性に問題がないか、障害は収束傾向にあるか、等を点検する。 テスト網羅性などに問題がない場合は、目標値自体が誤っているということも考えられる。 |
||||||||||||||||||||
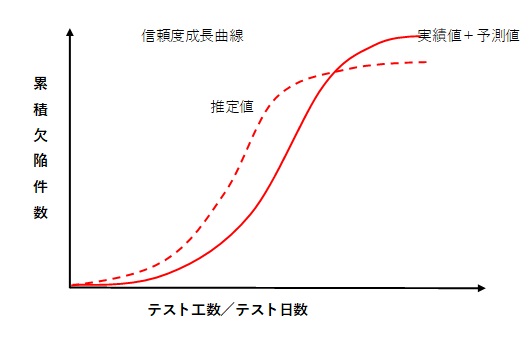 完了時点の予測値が目標値を上回る場合、 完了時点の予測値が目標値を上回る場合、障害の収束傾向と、障害の内容を分析する(障害の混入工程、原因分類、グループや担当者による層分析など)。 これらの分析で大きな問題がない場合は、目標値自体が誤っているということも考えられる。 |
||||||||||||||||||||
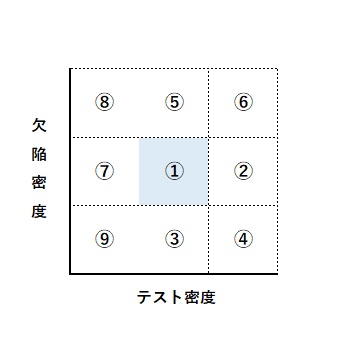
(2)ゾーン分析ゾーン分析とは、測定データをいくつかのグループ(ゾーン)に分類して分析するものである。
設計工程で、レビュー指摘密度とレビュー工数密度のゾーン分析を行う、などが代表的な例である。
|
||||||||||||||||||||
 |
||||||||||||||||||||
|
||||||||||||||||||||
|
|
||||||||||||||||||||
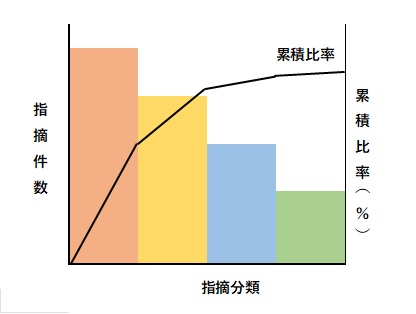
(3)パレート図パレート図は、障害を現象や原因などで分類し、その傾向をつかむ時などに使用する。
パレート図は、「QC7つ道具」のひとつである。また、ビジネスの世界では、パレートの法則(20:80の法則)として馴染み深い。(例えば、全体の2割の商品が売上げの8割を占める、などの経験則を指す)
ソフトウェアの障害分析の場面では、
・上位20%~30%を占める原因分類について対策を検討し、重点的に取り組む
・ある原因分類に対して対策を講じた場合、どの程度の効果が得られそうかを推測する
などの目的で使用される。
|
||||||||||||||||||||
 |
||||||||||||||||||||
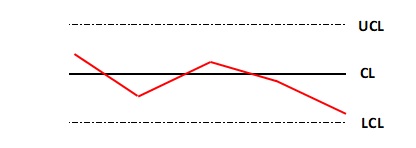
(4)管理図分析管理図分析とは、データの分布がUCLとLCLに対してどの位置にプロットされるかを見て、データが正常範囲内か、外れ値かを判断する方法である。
UCLは上部管理限界線(Upper Control Limit)、LCLは下部管理限界線(Lower Control Limit)で、それぞれ閾値の上限と下限を表す。
|
||||||||||||||||||||
|
|
||||||||||||||||||||
|
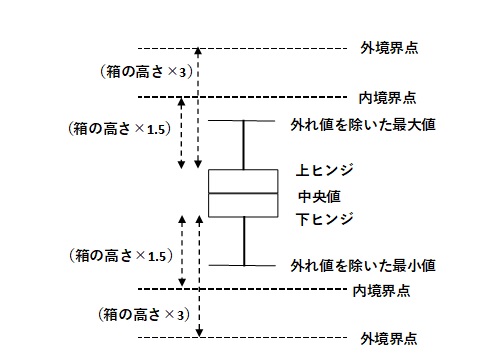
例えば、SECの「ソフトウェア開発データ白書では、UCLとLCLを中央値(CL:Center Line)から±25%としている。
これを箱ひげ図で表すと、
下ヒンジは、データを小さい順に並べたときに下から25%にあたるデータ
中央値は、データを小さい順に並べたときに中央にあたるデータ
上ヒンジは、データを小さい順に並べたときに下から75%にあたるデータ
である。
内境界点は、上ヒンジから「上下ヒンジ間の高さ×1.5」を足した値を境界として、そこを超過したデータを外れ値とみなす。下側の内境界点も同様である。
|
||||||||||||||||||||
 箱ひげ図 箱ひげ図 |
||||||||||||||||||||
|
|
||||||||||||||||||||